Text Scraping with Python – A Step By Step Tutorial
Jan 15

Introduction
In today’s data-driven world, accessing and utilizing data from the web is becoming increasingly important for businesses, researchers, and developers. Text Scraping is a powerful technique used to extract textual data from web pages for analysis, aggregation, or other applications. This comprehensive Text Scraping Guide will walk you through the process of Text Scraping with Python, introducing tools and techniques that will help you effectively scrape text from web pages.
What is Text Scraping?

Text Scraping refers to the process of extracting textual content from websites. Whether you're gathering reviews, collecting product details, or monitoring news trends, Web scraping text from websites can provide valuable insights. Python, with its extensive libraries and community support, is a popular choice for this task.
Why Use Python for Text Scraping?

Python is a versatile programming language with a rich ecosystem of libraries and tools for Text Scraping. Here are some reasons to choose Python:
- Ease of Use: Python's syntax is beginner-friendly and easy to understand.
- Comprehensive Libraries: Libraries like BeautifulSoup, Scrapy, and Requests simplify web scraping.
- Scalability: Python supports large-scale scraping with tools like Scrapy and Web Crawler frameworks.
- Integration: It integrates well with databases, APIs, and analytics tools for seamless workflows.
Prerequisites

Before diving into Text Scraping with Python, ensure you have the following:
- Python Installed: Install Python from python.org.
- Basic Python Knowledge: Familiarity with Python basics like loops and functions.
- Required Libraries: Install the following Python libraries:
- requests
- BeautifulSoup (from bs4)
- lxml
- pandas (optional, for data handling)
You can install these libraries using pip:
pip install requests beautifulsoup4 lxml pandas
Step-by-Step Guide to Text Scraping with Python
Step 1: Understanding the Target Website
Before you begin scraping, identify the structure of the website you want to scrape. Use browser developer tools (F12) to inspect the HTML elements of the web page. This helps in locating the desired tags for extracting data.
Step 2: Sending HTTP Requests
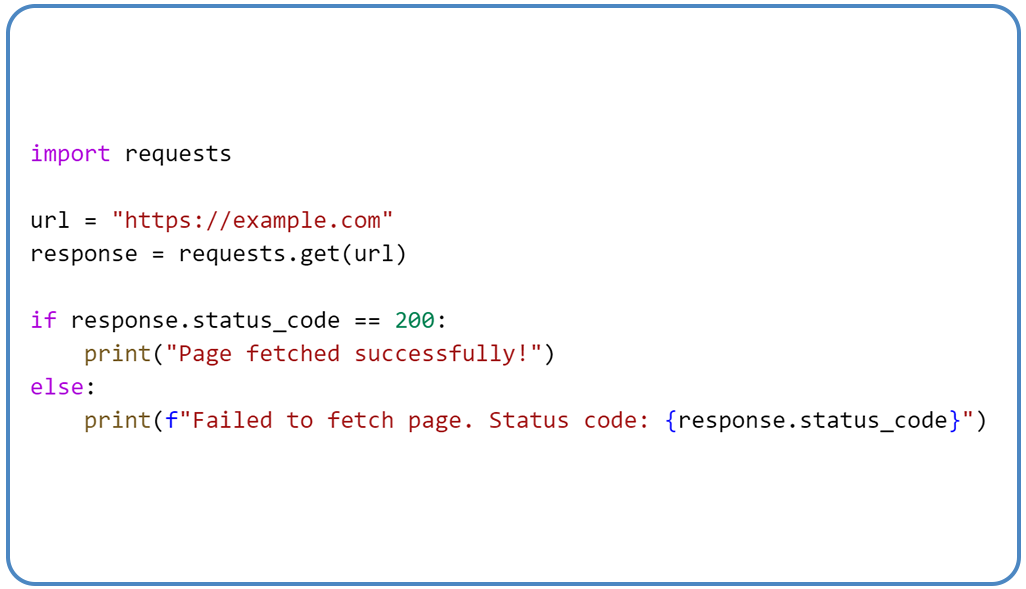
Use the requests library to send HTTP requests and fetch the web page content. Here’s an example:
Step 3: Parsing HTML with BeautifulSoup
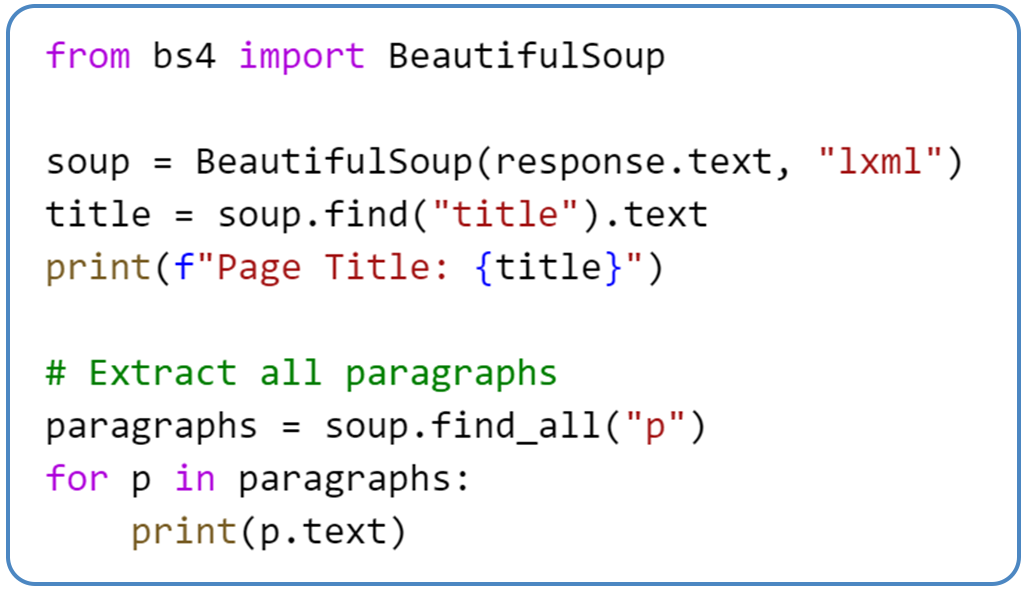
BeautifulSoup is a powerful library for parsing HTML content. It allows you to navigate and extract elements easily.
Step 4: Extracting Specific Data

Use CSS selectors or tag attributes to extract specific data. For example, extracting links from a page:
Step 5: Handling Dynamic Content
Some websites use JavaScript to load content dynamically. To scrape text from web pages with dynamic content, use Selenium or Scrapy:
- Selenium for browser automation.
- Scrapy for scalable scraping with a built-in Web Crawler.
Example with Selenium:
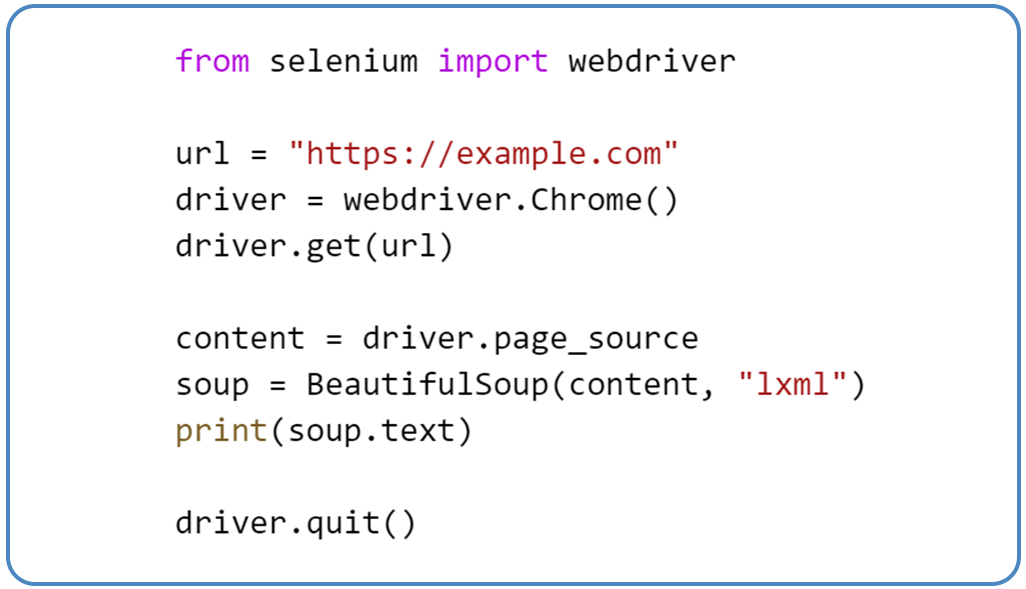
Step 6: Storing the Data

Store the scraped data in a structured format like CSV, JSON, or a database. Example of saving data to CSV:
Best Practices for Text Scraping

1. Respect Robots.txt: Always check the website's robots.txt file to ensure your scraping activities are allowed.
2. Avoid Overloading Servers: Use delays between requests to prevent server overload.
3. Use Proxies and Headers: Bypass scraping blocks by rotating proxies and setting user-agent headers.
4. Opt for a Scraper API: For large-scale scraping, a Scraper API provides efficient and reliable data extraction.
Advanced Topics
Using Scrapy for Large-Scale Scraping
Scrapy is a framework specifically designed for web scraping. It includes a built-in Web Crawler for navigating multiple pages and collecting data.
pip install scrapy Create a Scrapy project and define your spider to extract the desired data:

Leveraging Web Scraping Services

If you need robust and scalable solutions, consider using professional Web Scraping Services. These services provide tools, APIs, and infrastructure for efficient data extraction.
Mobile App Scraping
In addition to websites, you can scrape data from mobile apps using tools like APK decompilers or APIs. Ensure compliance with legal and ethical guidelines when performing Mobile App Scraping.
Common Challenges in Text Scraping

1. Captcha and Bot Detection: Use captcha solvers and randomized user agents to bypass restrictions.
2. Dynamic Loading: Handle JavaScript-based content with Selenium or Puppeteer.
3. Frequent Layout Changes: Monitor and update your scraper regularly to adapt to website changes.
Conclusion
Text Scraping with Python is a valuable skill for extracting and analyzing data from the web. By following this Text Scraping Guide, you can build efficient tools to scrape text from web pages while adhering to best practices. Whether you’re a beginner or an experienced developer, Python offers the flexibility and power needed for diverse scraping tasks.
If you’re looking for expert assistance or scalable solutions, consider partnering with Web Data Crawler, a trusted name in Web Scraping Services. Contact us today to unlock the potential of your data scraping projects!